
One common pattern we see repeatedly is how clients are transitioning their monolithic applications to distributed architectures. The challenge here is doing that while still retaining the data on the main database for consistency and other coupled systems. Implementing microservices gets a bit tricky. We suddenly need to have a copy of the data and keep it consistent.
Initial snapshot
Often teams take this exercise to rethink the way they handle schema. So cloning tables to the new database and calling it a day does not cut it. We’d like to be able to use new microservice not only as a fancy DB proxy, but also as a model for future state. Since we don’t always know what the future state will look like, ingesting all data in one go might be too much of commitment. The is where incrementally building microservice-specific data store comes in handy. As requests flow through our system, we’d fulfill them from the Monolith but keep a copy and massage for efficiency.
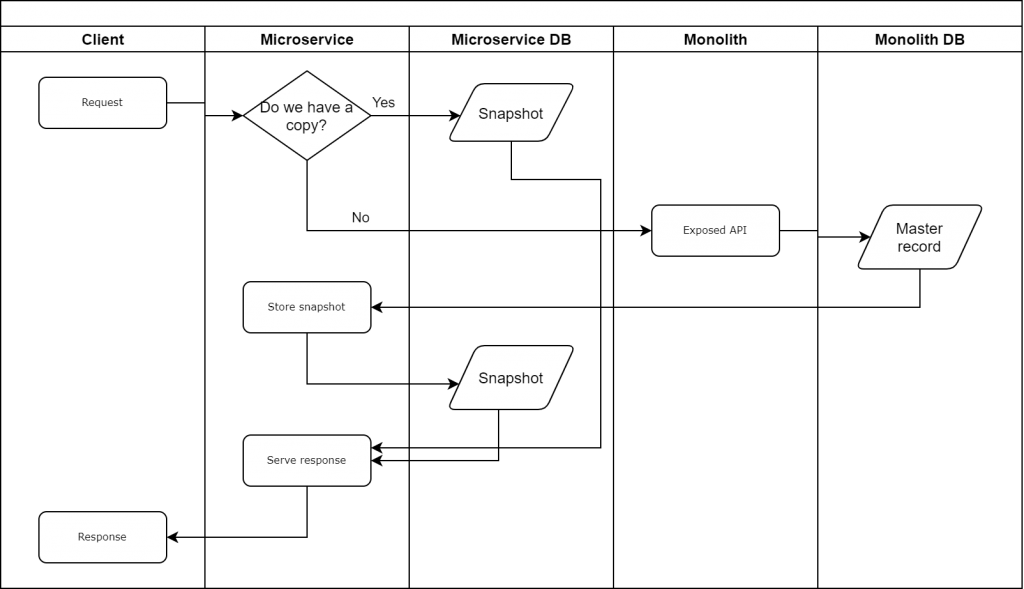
Updates go here
There’s no question we need some way to let our microservices know that something has gotten updated. A message queue of sorts will likely do. So next time the Monolith updates an entity we’re interested in – we’d get a message:
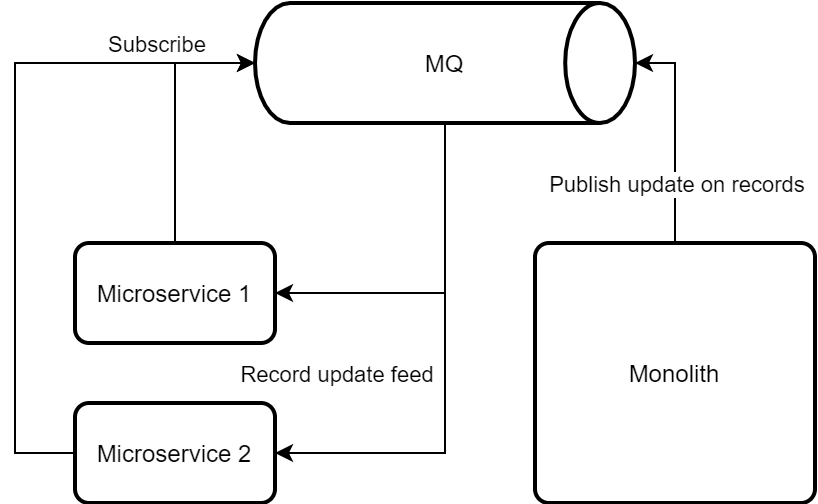
As we progress
The schematic above can be extended to allow monolith be part of receiving the update feeds too. When we are ready to commit to moving System of Record to a microservice – we reverse the flow and have Monolith listen to changes and update “master” record accordingly. Only at that time it won’t be “master” anymore.
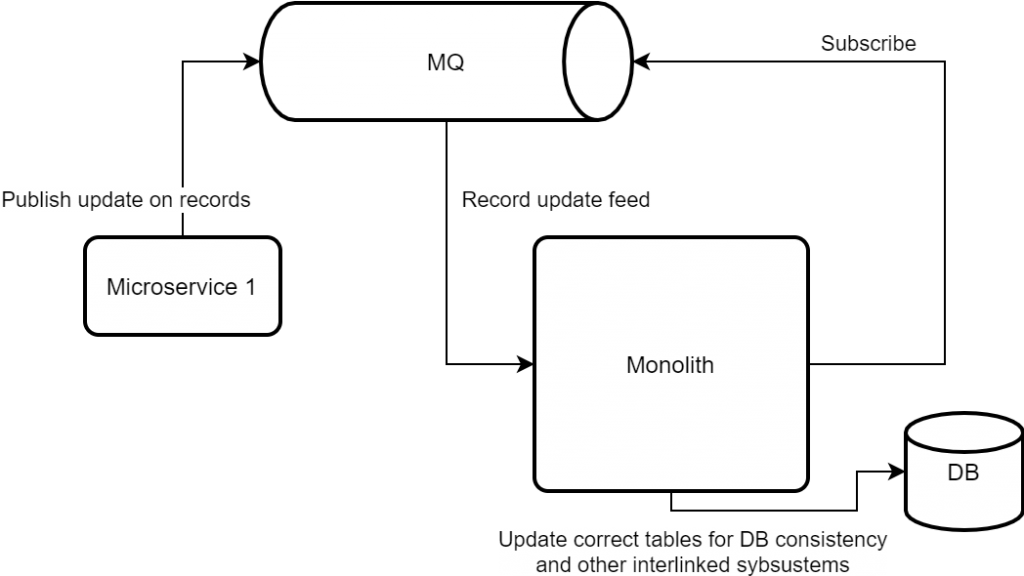
Choice of Message Bus
We’d need to employ a proper message bus for this flow to work. There are quite a few options out there and picking a particular one without considering trade-offs is meaningless. We prefer to keep our options limited to RabbitMQ and Kafka. A few reasons to pick one or another are: community size, delivery guarantees and scalability constraints. Stay tuned for an overview of those!
One thought on “Breaking down the Monolith: data flows”
Comments are closed.