As part of our technical debt collection commitment we do deal with weird situations where simply running a solution in Visual Studio might not be enough. A recent example to that was a web application split into two projects:
- ASP.NET MVC – provided a shell for SPA as well as all backend integration – the entry point for application
- React with Webpack – SPA mostly responsible for the UI and user intercations. Project was declared as Class Library with no code to run, while developers managed all javascript and Webpack off-band
Both projects are reasonably complex and I can see why the developers tried to split them. The best intention however makes running this tandem a bit awkward execrise. We run npm run build and expect it to drop files into correct places for MVC project that just relies on compiled javascript to be there. Using both technology stacks in one solution is nothing new. We’d have opted for this template back at project inception. Now was too late however.
Just make VS run both projects
Indeed, Microsoft has been generous enough to let us designate multiple projects as start up:
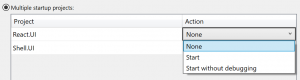
This however does not help our particular case as React project was created as Class Library and there’s no code to run. We need a way to kick that npm run build command line every time VS ‘builds’ the React project… How do we do it?
Okay, let’s use custom Start Action
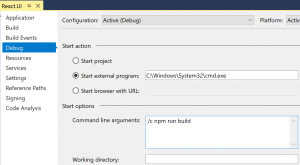
Bingo! We can absolutely do this and bootstrap us a shell which then would run our npm command. Technically we can run npm directly, but I could never quite remember where to look for the executable.
There’s a slight issue with this approach though: it is not portable between developers’ machines. There are at least two reasons for that:
- Input boxes on this dialog form do not support environment variables and/or relative paths.
- Changes made in ths window go to .csproj.user file, that by default is .gitignore’d (here’s a good explanation why it should be)
So this does not work:
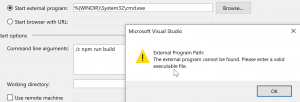
There might be a way however
- First and foremost, unload the solution (not just project). Project .user settings are loaded on solution start so we want it to be clean.
- Open up .user file in your favourite text editor, mine looks like this:
Program
C:\Windows\System32\cmd.exe
/c start /min npm run buildAnd change the path to whatever your requirements are:
Program
$(WINDIR)\System32\cmd.exe
/c start /min npm run buildWe could potentially stop here, but the file is still user-specific and is not going into source control.
Merging all the way up to project file
As it turns out, we can just cut the elements we’re after (StartAction, StartProgram and StartArguments) and paste them into respective .csproj section (look out for the same Condition on PropertyGroup, that should be it)
true
full
false
bin\Debug\
DEBUG;TRACE
prompt
4
Program
$(WINDIR)\System32\cmd.exe
/c start /min npm run buildOpen the solution again and check if everything works as intended.
