
This is the second part of the series following our humble endeavors to automate Terraform deployment tasks. First part here. With housekeeping out of the way, let’s get on to the content.
For purposes of this exercise, it does not matter what we want to deploy. Can be a simple Web App or full fat Landing Zone. The pipeline itself remains unchanged.
Sample Infrastructure
Since we want an absolute minimum, we’ll go with one resource group and one Static Web App:
#============= main.tf ====================
terraform {
backend "azurerm" { }
required_providers {
azurerm = {
version = "~> 2.93"
}
}
}
# Set target subscription for deployment
provider "azurerm" {
features {}
subscription_id = var.subscription_id
}
#============= infra.tf ====================
resource "azurerm_resource_group" "main" {
name = "${var.prefix}-${var.environment}-${var.location}-workload-rg"
location = var.location
}
resource "azurerm_static_site" "main" {
name = "${var.prefix}-${var.environment}-${var.location}-swa"
resource_group_name = azurerm_resource_group.main.name
location = var.location
}We’ll focus on the pipeline though
Since our goal is to have as little human intervention as possible, we went with multi-stage YAML pipeline.
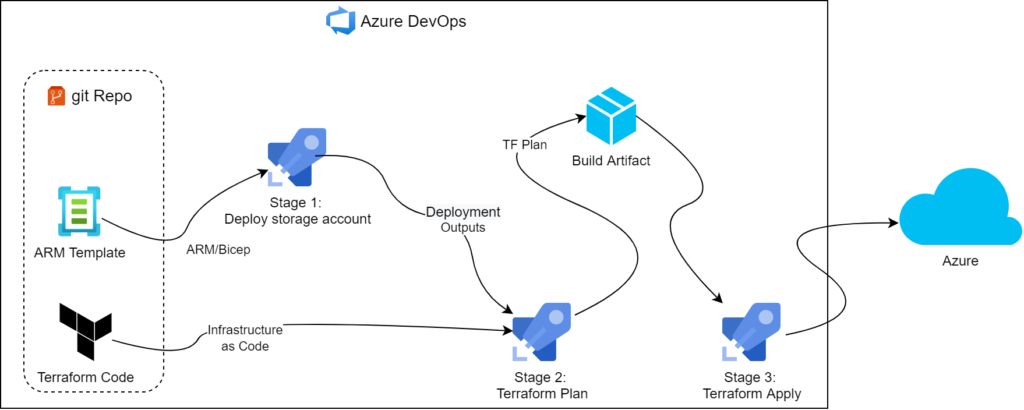
the YAML may look something like that:
trigger: none # intended to run manually
name: Deploy Terraform
pool:
vmImage: 'ubuntu-latest'
variables:
- group: 'bootstrap-state-variable-grp'
stages:
- stage: bootstrap_state
displayName: 'Bootstrap TF State'
jobs:
- job: tf_bootstrap
steps:
- task: AzureResourceManagerTemplateDeployment@3
inputs:
deploymentScope: 'Subscription'
azureResourceManagerConnection: '$(azureServiceConnection)'
subscriptionId: '$(targetSubscriptionId)'
location: '$(location)'
csmFile: '$(Build.SourcesDirectory)/bicep/main.bicep' # on dev machine, compile into ARM (az bicep build --file .\bicep\main.bicep) and use that instead until agent gets update to 3.199.x
deploymentOutputs: 'deploymentOutputs'
overrideParameters: '-prefix $(prefix) -location $(location)'
- script: |
# this script takes output from ARM deployment and makes it available to steps further down the pipeline
echo "##vso[task.setvariable variable=resourceGroupName;isOutput=true]`echo $DEPLOYMENT_OUTPUT | jq -r '.resourceGroupName.value'`"
echo "##vso[task.setvariable variable=storageAccountName;isOutput=true]`echo $DEPLOYMENT_OUTPUT | jq -r '.storageAccountName.value'`"
echo "##vso[task.setvariable variable=containerName;isOutput=true]`echo $DEPLOYMENT_OUTPUT | jq -r '.containerName.value'`"
echo "##vso[task.setvariable variable=storageAccessKey;isOutput=true;isSecret=true]`echo $DEPLOYMENT_OUTPUT | jq -r '.storageAccessKey.value'`"
# https://docs.microsoft.com/en-us/azure/devops/pipelines/process/variables?view=azure-devops&tabs=yaml%2Cbatch#share-variables-across-pipelines
name: armOutputs # giving name to this task is extremely important as we will use it to reference the variables from later stages
env:
DEPLOYMENT_OUTPUT: $(deploymentOutputs)
- stage: run_tf_plan # Build stage
displayName: 'TF Plan'
jobs:
- job: tf_plan
variables:
# to be able to reference outputs from earlier stage, we start hierarchy from stageDependencies and address job outputs by full name: <stage_id>.<job_id>.outputs
- name: resourceGroupName
value: $[ stageDependencies.bootstrap_state.tf_bootstrap.outputs['armOutputs.resourceGroupName'] ]
- name: storageAccountName
value: $[ stageDependencies.bootstrap_state.tf_bootstrap.outputs['armOutputs.storageAccountName'] ]
- name: containerName
value: $[ stageDependencies.bootstrap_state.tf_bootstrap.outputs['armOutputs.containerName'] ]
- name: storageAccessKey
value: $[ stageDependencies.bootstrap_state.tf_bootstrap.outputs['armOutputs.storageAccessKey'] ]
steps:
# check out TF code from git
- checkout: self
persistCredentials: true
# init terraform and point the backend to correct storage account
- task: TerraformTaskV2@2 # https://github.com/microsoft/azure-pipelines-extensions/blob/master/Extensions/Terraform/Src/Tasks/TerraformTask/TerraformTaskV2/task.json
displayName: terraform init
inputs:
workingDirectory: '$(System.DefaultWorkingDirectory)/tf'
backendServiceArm: $(azureServiceConnection)
backendAzureRmResourceGroupName: $(resourceGroupName)
backendAzureRmStorageAccountName: $(storageAccountName)
backendAzureRmContainerName: $(containerName)
backendAzureRmKey: '$(prefix)/terraform.tfstate'
env:
ARM_ACCESS_KEY: $(storageAccessKey)
# run terraform plan and store it as a file so we can package it
- task: TerraformTaskV2@2
displayName: terraform plan
inputs:
workingDirectory: '$(System.DefaultWorkingDirectory)/tf'
environmentServiceNameAzureRM: $(azureServiceConnection)
command: 'plan'
# feed tfvars file and set variables for azure backend (see TF files for usage)
commandOptions: '-input=false -var-file=terraform.tfvars -var="prefix=$(prefix)" -var="location=$(location)" -var="subscription_id=$(targetSubscriptionId)" -out=$(prefix)-plan.tfplan'
env:
ARM_ACCESS_KEY: $(storageAccessKey)
# package workspace into an artifact so we can publish it
- task: ArchiveFiles@2
inputs:
displayName: 'Create Plan Artifact'
rootFolderOrFile: '$(System.DefaultWorkingDirectory)/tf'
includeRootFolder: false
archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip'
replaceExistingArchive: true
# publish artifact to ADO
- task: PublishBuildArtifacts@1
inputs:
displayName: 'Publish Plan Artifact'
PathtoPublish: '$(Build.ArtifactStagingDirectory)'
ArtifactName: '$(Build.BuildId)-tfplan'
publishLocation: 'Container'
- stage: run_tf_apply # Deploy stage
dependsOn:
- bootstrap_state # adding extra dependencies so we can access armOutputs from earlier stages
- run_tf_plan # by default next stage would have depended on the previous, but we broke that chain by depending on earlier stages
displayName: 'TF Apply'
jobs:
- deployment: tf_apply
variables:
# to be able to reference outputs from earlier stages, we start hierarchy from stageDependencies and address job outputs by full name: <stage_id>.<job_id>.outputs
- name: storageAccessKey
value: $[ stageDependencies.bootstrap_state.tf_bootstrap.outputs['armOutputs.storageAccessKey'] ]
environment: 'dev' # required for deployment jobs. will need to authorise the pipeline to use it at first run
strategy:
runOnce:
deploy:
steps:
# grab published artifact
- task: DownloadBuildArtifacts@0
inputs:
artifactName: '$(Build.BuildId)-tfplan'
displayName: 'Download Plan Artifact'
# unpack the archive, we should end up with all necessary files in root of working directory
- task: ExtractFiles@1
inputs:
archiveFilePatterns: '$(System.ArtifactsDirectory)/$(Build.BuildId)-tfplan/$(Build.BuildId).zip'
destinationFolder: '$(System.DefaultWorkingDirectory)/'
cleanDestinationFolder: false
displayName: 'Extract Terraform Plan Artifact'
- task: TerraformTaskV2@2
displayName: terraform apply
inputs:
workingDirectory: $(System.DefaultWorkingDirectory)
command: 'apply'
commandOptions: '-auto-approve -input=false $(prefix)-plan.tfplan'
environmentServiceNameAzureRM: $(azureServiceConnection)
env:
ARM_ACCESS_KEY: $(storageAccessKey)Couple of notes regarding the pipeline
The pipeline is pretty straightforward so instead of going through it line by line, we just wanted to point out a few things that really helped us put this together
armOutputsis where we capture JSON outputs and feed them to pipeline.- Building on top of that, we had to import these variables in subsequent stages using stage dependencies. The pipeline can ultimately be represented as a tree containing stages on top level and ending with tasks as leaves. Keywords
dependenciesandstageDependenciestell us which level we’re looking at - For this trick to work, the requesting stage must depend on the stage where variables are exported from. By default, subsequent stages depend on the stages immediately preceding them. But in more complicated scenarios we can use
dependsOnparameter and specify it ourselves. - Keen-eyed readers may notice we do not perform Terraform Install at all. This is very intentional, as Hosted Agent we’re using for this build already has TF 1.1.5 installed. It’s good enough for us but may need an upgrade in your case
- The same point applies to using
jqin our JSON parsing script – it’s already in there but your mileage may vary
Conclusion
With the build pipeline sorted, we’re yet another step closer to our zero-touch Terraform deployment nirvana. We already can grab the code and commit it into a fresh ADO project to give our workflow a boost. I’m not sharing the code just yet as there are still a couple of things we can do, so watch this space for more content!