It is somewhat common for our clients to come to us for small website deployments. They’re after landing pages, or single page apps so they can put something up quickly at minimal cost.
There are options
Azure, as our platform of choice, offers many ways to deploy static content. We have talked about some ways to host simple pages before, but this time round, let’s throw BYO domains and SSL into the mix, evaluate upgrade potential, and compare costs. One extra goal we have set for ourselves was to build IaC via Terraform for each option so we can streamline our process further.
Since BYO domains require manual setup and validation, we opted to manually create a parent DNS zone, validate it prior to running Terraform and let the code automagically create child zone for our experiments. Real setups may differ.
Storage + CDN
The first method relies on Azure Storage Account feature where it can serve content of a container via HTTP or HTTPS. There’s no operational cost for this feature – we only pay for consumed storage. The drawback of this design is lack of support for managed SSL certs on custom domains. Prescribed architecture works around this by adding CDN in front of it and we found that the associated cost is likely going to be negligible for simple static pages (we’re talking $0.13 per 100Gb on top of standard egress charges). That said, the egress bill itself can potentially blow out if left unchecked.
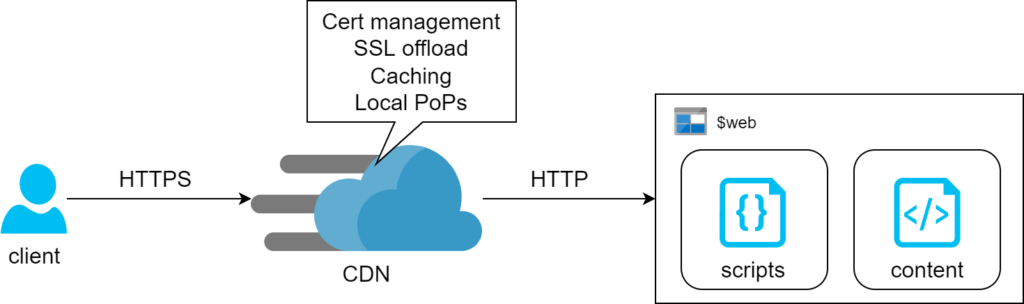
A few notes on automation
Switching static website feature is considered a data plane exercise, so ARM templates are of little help. Terraform, however supports this with just a couple lines of config:
resource "azurerm_storage_account" "main" {
name = "${replace(var.prefix, "/[-_]/", "")}${lower(random_string.storage_suffix.result)}"
resource_group_name = azurerm_resource_group.main.name
location = azurerm_resource_group.main.location
account_tier = "Standard"
account_replication_type = "LRS"
static_website { // magic
index_document = "index.html"
}
}Another neat thing with Terraform, it allows for uploading files to storage with no extra steps:
resource "azurerm_storage_blob" "main" {
name = "index.html"
storage_account_name = azurerm_storage_account.main.name
storage_container_name = "$web"
type = "Block"
content_type = "text/html"
source = "./content/index.html"
}Secondly, CDN requires two CNAME domains for custom domain to work: the subdomain itself and one extra for verification. Nothing overly complicated, we just need to make sure we script both:
resource "azurerm_dns_cname_record" "static" {
name = "storage-account"
zone_name = azurerm_dns_zone.static.name
resource_group_name = azurerm_resource_group.main.name
ttl = 60
record = azurerm_cdn_endpoint.main.host_name
}
resource "azurerm_dns_cname_record" "static_cdnverify" {
name = "cdnverify.storage-account"
zone_name = azurerm_dns_zone.static.name
resource_group_name = azurerm_resource_group.main.name
ttl = 60
record = "cdnverify.${azurerm_cdn_endpoint.main.host_name}"
}Finally, CDN takes a little while to deploy a custom domain (seems to get stuck with verification) – ours took 10 minutes to complete this step.
Static Web App
This is probably the most appropriate way to host static content in Azure. Not only it supports serving content, it also comes with built-in Functions and Authentication. We also get CDN capabilities out of the box and on top of that it is usable on free tier. This definitely is our platform of choice.
Since we’ve already covered Static Web Apps we’d just briefly touch upon automating it with Terraform. The only complication here is that native azurerm_static_site is perfectly capable of standing up the resource but has no idea on how to deploy content. Since there’s no supported way of manually uploading content, we opted for docker deployment. Fitting it back into the pipeline was a bit of a hack, which is essentially a shell script to run when content changes:
resource "null_resource" "publish_swa" {
triggers = {
script_checksum = sha1(join("", [for f in fileset("content", "*"): filesha1("content/${f}")])) // recreate resource on file checksum change. This will always trigger a new build, so we don't care about the state as much
}
provisioner "local-exec" {
working_dir = "${path.module}"
interpreter = ["bash", "-c"]
command = <<EOT
docker run --rm -e INPUT_AZURE_STATIC_WEB_APPS_API_TOKEN=${azurerm_static_site.main.api_key} -e DEPLOYMENT_PROVIDER=DevOps -e GITHUB_WORKSPACE=/working_dir -e INPUT_APP_LOCATION=. -v `pwd`/content:/working_dir mcr.microsoft.com/appsvc/staticappsclient:stable ./bin/staticsites/StaticSitesClient upload --verbose true
EOT
}
// the block above assumes static content sits in `./content` directory. Using `pwd` with backticks is particularly important as terraform attempts parsing ${pwd} syntax, while we need to pass it into the shell
depends_on = [
azurerm_static_site.main
]
}
App Service
Finally comes the totally overengineered approach that will also be the most expensive and offers no regional redundancy by default. Using App Service makes no sense for hosting simple static pages but may come in handy as a pattern for more advanced scenarios like containers or server-side-rendered web applications.
Notes on building it up
For this exercise we opted to host our content in a simple nginx docker container. Linux App Service plans with Custom Domain and SSL support start from $20/month, so they are not cheap. We started with scaffolding a Container Registry, where we’d push a small container so that App Service can pull it on startup:
FROM nginx:alpine
WORKDIR /usr/share/nginx/html/
COPY index.html .
COPY ./nginx.conf /etc/nginx/nginx.conf # there's minimal nginx config, check out github
EXPOSE 80 # we only care to expose HTTP endpoint, so no certs are needed for nginx at this stageWe picked Nginx because of its simplicity and low overheads to illustrate our point. But since we can containerise just about anything, this method becomes useful for more complicated deployments.
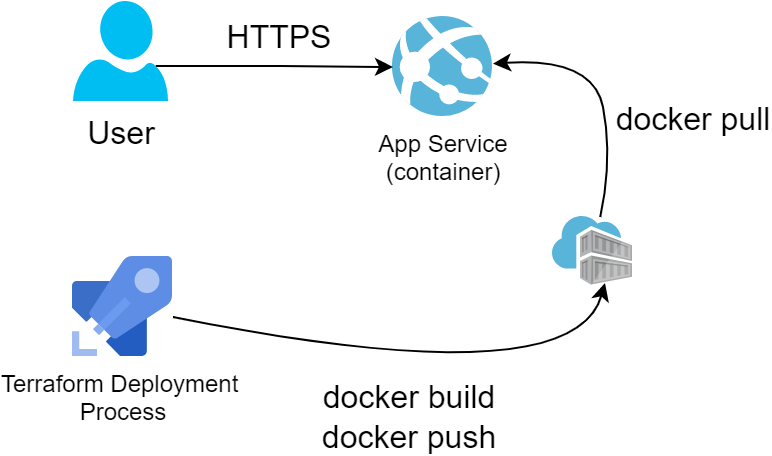
resource "null_resource" "build_container" {
triggers = {
script_checksum = sha1(join("", [for f in fileset("content", "*"): filesha1("content/${f}")])) // the operation will kick in on change to any of the files in content directory
}
// normal build-push flow for private registry
provisioner "local-exec" { command = "docker login -u ${azurerm_container_registry.acr.admin_username} -p ${azurerm_container_registry.acr.admin_password} ${azurerm_container_registry.acr.login_server}" }
provisioner "local-exec" { command = "docker build ./content/ -t ${azurerm_container_registry.acr.login_server}/static-site:latest" }
provisioner "local-exec" { command = "docker push ${azurerm_container_registry.acr.login_server}/static-site:latest" }
provisioner "local-exec" { command = "docker logout ${azurerm_container_registry.acr.login_server}" }
depends_on = [
azurerm_container_registry.acr
]
}
resource "azurerm_app_service" "main" {
name = "${var.prefix}-app-svc"
location = azurerm_resource_group.main.location
resource_group_name = azurerm_resource_group.main.name
app_service_plan_id = azurerm_app_service_plan.main.id
app_settings = {
WEBSITES_ENABLE_APP_SERVICE_STORAGE = false // this is required for Linux app service plans
DOCKER_REGISTRY_SERVER_URL = azurerm_container_registry.acr.login_server // the convenience of rolling ACR with terraform is that we literally have all the variables already available
DOCKER_REGISTRY_SERVER_USERNAME = azurerm_container_registry.acr.admin_username // App Service uses admin account to pull container images from ACR. We have to enable it when defining the resource
DOCKER_REGISTRY_SERVER_PASSWORD = azurerm_container_registry.acr.admin_password
}
site_config {
linux_fx_version = "DOCKER|${azurerm_container_registry.acr.name}.azurecr.io/static-site:latest"
always_on = "true" // this is also required on Linux app service plans
}
depends_on = [
null_resource.build_container
]
}Conclusion
Going through this exercise, we’ve built a bit of a decision matrix on which service to use:
| App Service | Storage Account | Static Web App | |
| Fit for purpose | not really | ✅ | ✅ |
| AuthN/AuthZ | Can be done within the app | ❌ | Built-in OpenID Connect |
| Global scale | ❌ | ✅ (via CDN) | ✅ |
| Upgrade path to consuming API | ✅(DIY) | ❌ | ✅ (built in Functions or BYO Functions) |
| Indicative running costs (per month) except egress traffic | $20+ | ~$0 (pay for storage), but CDN incurs cost per GB transferred | $0 or $9 (premium tier, for extra features) |
| Tooling support | No significant issues with either ARM or Terraform | Enabling static websites in ARM is awkward (albeit possible), Terraform is fine though | No official way to deploy from local machine (but can be reliably worked around). Requires CI/CD with GitHub or ADO |
As always, full code is on GitHub, infrastructure-as-coding.