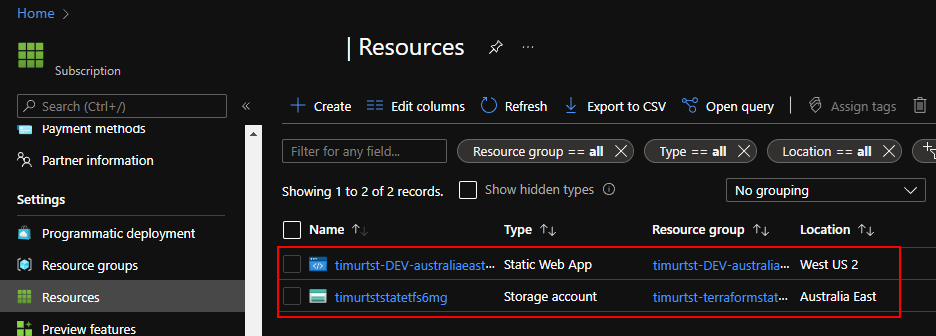
Last time we traced the signing logic to Po.c, discovered the secrets come from a native library that decodes them at runtime, and hit a wall trying to statically reverse the XOR encoding. Time for plan B — if we can’t reverse the encoding, we’ll just read the decoded values from memory.
Why the obvious approaches don’t work
Before reaching for Frida, we tried a few shortcuts:
| Approach | Result |
|---|---|
Call Secrets.getXxx() directly | Needs an instance, not static |
Create new Secrets() instance | Native code only decodes at init |
| Hook the constructor | App has anti-Frida detection, crashes |
Reverse XOR in the .so | Position-dependent key, too complex |
The key insight: the app has already decoded the secrets and stored them in a Po.c instance sitting on the heap. We don’t need to trigger the decoding — we just need to find that instance and read its fields.
Heap scanning with Java.choose()
Frida’s Java.choose() walks the heap looking for live instances of a given class. Combined with reflection to bypass private field access, it’s exactly what we need:
Java.perform(function() {
var PoC = Java.use("Po.c");
var aField = PoC.class.getDeclaredField("a");
var bField = PoC.class.getDeclaredField("b");
var cField = PoC.class.getDeclaredField("c");
aField.setAccessible(true);
bField.setAccessible(true);
cField.setAccessible(true);
Java.choose("Po.c", {
onMatch: function(instance) {
console.log("partnerKey: " + aField.get(instance));
console.log("algorithmKey: " + bField.get(instance));
console.log("algorithmName: " + cField.get(instance));
},
onComplete: function() {}
});
});sequenceDiagram
participant F as Frida
participant H as JVM Heap
participant I as Po.c instance
F->>H: Java.choose("Po.c")
H->>F: Found instance
F->>I: reflection — get field "a"
I-->>F: partnerKey
F->>I: reflection — get field "b"
I-->>F: algorithmKey
F->>I: reflection — get field "c"
I-->>F: algorithmName = HmacSHA1Running the extraction
# Push frida-server to the device
adb push frida-server /data/local/tmp/
adb shell "chmod 755 /data/local/tmp/frida-server"
adb shell "/data/local/tmp/frida-server &"
# Launch the app and wait for it to fully load
adb shell am start -n com.example.app/.presentation.ui.MainActivity
# Attach and extract
frida -U -n "TargetApp" -l get_instance.jsAnd there it is — all three values printed to the console. The algorithm name was HmacSHA1, not HmacSHA256 as we’d assumed from static analysis. That one wrong assumption would have produced invalid signatures every time.
The takeaway
graph TD
A["Static analysis — JADX + Apktool"] -->|finds| B["Where secrets live
How signing works"]
C["Dynamic analysis — Frida"] -->|finds| D["Actual secret values
Actual algorithm"]
B --> E["Complete picture"]
D --> EStatic analysis tells you how the code works. Dynamic analysis tells you what it’s working with. For anything involving runtime-decoded secrets or obfuscated native code, you need both. We spent hours tracing through decompiled Java to understand the signing flow, and then five lines of Frida script gave us the actual values in seconds. The full toolkit: JADX for decompilation, Apktool for resources, Frida for runtime extraction. And a healthy distrust of your own assumptions. If you’re also interested in intercepting app traffic, we covered SSL unpinning on Android in a separate post.