This article is part of the C# Advent Series. Christmas has a special place in our hearts and this event is also a wonderful way to help build up the C# community. Do check out awesome content from other authors!
There’s a couple of things about Christmas in Southern Hemisphere that tends to hit us pretty hard each year: first, the fact that it is summer and it’s scorching hot outside. And second – is a customary closedown of almost all businesses (which probably started as response to the first point). Some businesses, however, keep boxing on.
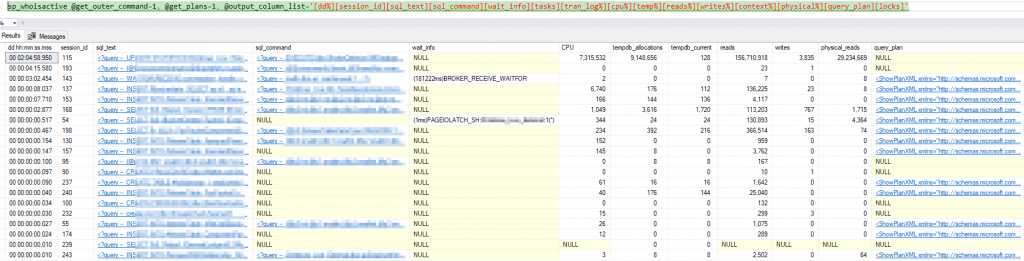
One of our clients is into cryptocurrency mining and they could not care less about staff wanting time off to spend with family. Their only workforce are GPUs, and these devices can work 24/7. However, with temperatures creeping up, efficiency takes a hit. Also, other sad things can happen:

Solution design
Our first suggestion was to use our trusty ELK+G and poll extra data from NVIDIA SMI tool, but we soon figured out that this problem has already been solved for us. Mining software nowadays got extremely sophisticated (and obfuscated) – it now comes with own webserver and API. So, we simplified a bit:
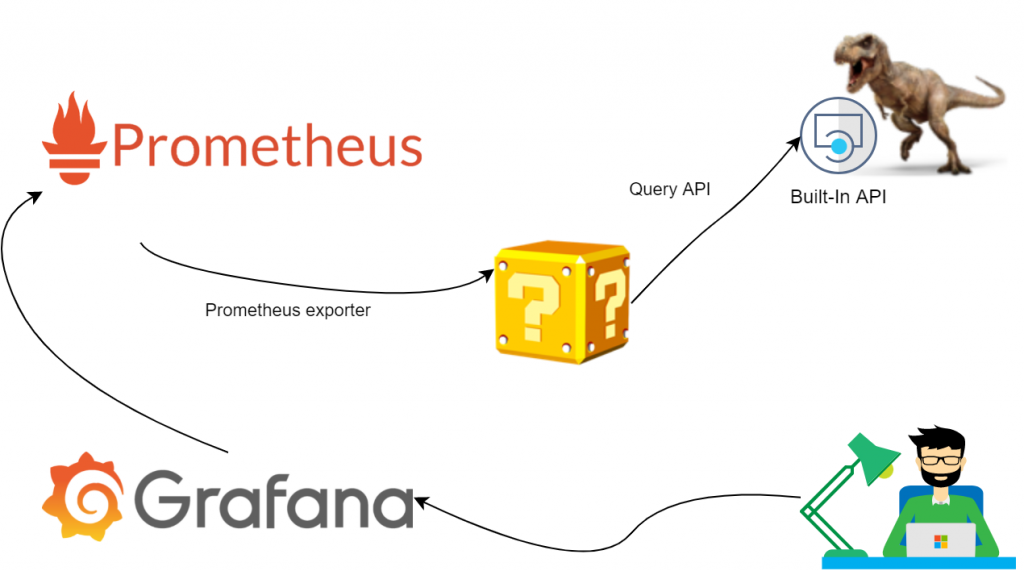
All we have to do here would be to stand up an exporter and set up a few dashboards. Easy.
Hosted Services
We essentially need to run two services: poll underlying API and expose metrics in Prometheus-friendly format. We felt .NET Core Generic host infrastructure would fit very well here. It allows us to bootstrap an app, add Hosted Services and leave plumbing to Docker. The program ended up looking like so:
class Program
{
private static async Task Main(string[] args)
{
using IHost host = CreatHostBuilder(args).Build();
await host.RunAsync();
}
static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureAppConfiguration((configuration) =>
{
configuration.AddEnvironmentVariables("TREX")
; // can add more sources such as command line
})
.ConfigureServices(c =>
{
c.AddSingleton<MetricCollection>(); // This is where we will keep all metrics state. hence singleton
c.AddHostedService<PrometheusExporter>(); // exposes MetricCollection
c.AddHostedService<TRexPoller>(); // periodically GETs status and updates MetricCollection
});
}Defining services
The two parts of our applicatgion are TRexPoller and PrometheusExporter. Writing both is trivial and we won’t spend much time on the code there. Feel free to check it out on GitHub. The point to make here is it has never been easier to focus on business logic and leave heavy lifting to respective NuGet packages.
Crafting the models
The most important part of our application is of course telemetry. We grabbed a sample json response from the API and used an online tool to convert that into C# classes:
// generated code looks like this. A set of POCOs with each property decorated with JsonProperty that maps to api response
public partial class Gpu
{
[JsonProperty("device_id")]
public int DeviceId { get; set; }
[JsonProperty("hashrate")]
public int Hashrate { get; set; }
[JsonProperty("hashrate_day")]
public int HashrateDay { get; set; }
[JsonProperty("hashrate_hour")]
public int HashrateHour { get; set; }
...
}Now we need to define metrics that Prometheus.Net can later discover and serve up:
// example taken from https://github.com/prometheus-net/prometheus-net#quick-start
private static readonly Counter ProcessedJobCount = Metrics
.CreateCounter("myapp_jobs_processed_total", "Number of processed jobs.");
...
ProcessJob();
ProcessedJobCount.Inc();Turning on lazy mode
This is where we’ve got so inspired by our “low code” solution that we didn’t want to get down to hand-crafting a bunch of class fields to describe every single value the API serves. Luckily, C#9 has a new feature just for us: Source Code Generators to the rescue! We’ve covered the basic setup before, so we’ll skip this part here and move on to the Christmas magic part.
Let Code Generators do the work for us
Before we hand everything over to robots, we need to set some basic rules to control the process. Custom attributes looked like a sensible way to keep all configuration local with the model POCOs:
[AddInstrumentation("gpus")] // the first attribute prompts the generator to loop through the properties and search for metrics
public partial class Gpu
{
[JsonProperty("device_id")]
public int DeviceId { get; set; }
[JsonProperty("hashrate")]
/*
* the second attribute controls which type the metric will have as well as what labels we want to store with it.
* In this example, it's a Gauge with gpu_id, vendor and name being labels for grouping in Prometheus
*/
[Metric("Gauge", "gpu_id", "vendor", "name")]
public int Hashrate { get; set; }
[JsonProperty("hashrate_day")]
[Metric("Gauge", "gpu_id", "vendor", "name")]
public int HashrateDay { get; set; }
[JsonProperty("hashrate_hour")]
[Metric("Gauge", "gpu_id", "vendor", "name")]
public int HashrateHour { get; set; }
Finally, the generator itself hooks into ClassDeclarationSyntax and looks for well-known attributes:
public void OnVisitSyntaxNode(SyntaxNode syntaxNode)
{
if (syntaxNode is ClassDeclarationSyntax cds && cds.AttributeLists
.SelectMany(al => al.Attributes)
.Any(a => (a.Name as IdentifierNameSyntax)?.Identifier.ValueText == "AddInstrumentation"))
{
ClassesToProcess.Add(cds);
}
}
Once we’ve got our list, we loop through each property and generate a dictionary of Collector objects.
var text = new StringBuilder(@"public static Dictionary<string, Collector> GetMetrics(string prefix)
{
var result = new Dictionary<string, Collector>
{").AppendLine();
foreach (PropertyDeclarationSyntax p in properties)
{
var jsonPropertyAttr = p.GetAttr("JsonProperty");
var metricAttr = p.GetAttr("Metric");
if (metricAttr == null) continue;
var propName = jsonPropertyAttr.GetFirstParameterValue();
var metricName = metricAttr.GetFirstParameterValue(); // determine metric type
if (metricAttr.ArgumentList.Arguments.Count > 1)
{
var labels = metricAttr.GetTailParameterValues(); // if we have extra labels to process - here's our chance
text.AppendLine(
$"{{$\"{{prefix}}{attrPrefix}_{propName}\", Metrics.Create{metricName}($\"{{prefix}}{attrPrefix}_{propName}\", \"{propName}\", {commonLabels}, {labels}) }},");
}
else
{
text.AppendLine(
$"{{$\"{{prefix}}{attrPrefix}_{propName}\", Metrics.Create{metricName}($\"{{prefix}}{attrPrefix}_{propName}\", \"{propName}\", {commonLabels}) }},");
}
}
text.AppendLine(@"};
return result;
}");In parallel to defining storage for metrics, we also need to generate code that will update values as soon as we’ve heard back from the API:
private StringBuilder UpdateMetrics(List<MemberDeclarationSyntax> properties, SyntaxToken classToProcess, string attrPrefix)
{
var text = new StringBuilder($"public static void UpdateMetrics(string prefix, Dictionary<string, Collector> metrics, {classToProcess} data, string host, string slot, string algo, List<string> extraLabels = null) {{");
text.AppendLine();
text.AppendLine(@"if(extraLabels == null) {
extraLabels = new List<string> {host, slot, algo};
}
else {
extraLabels.Insert(0, algo);
extraLabels.Insert(0, slot);
extraLabels.Insert(0, host);
}");
foreach (PropertyDeclarationSyntax p in properties)
{
var jsonPropertyAttr = p.GetAttr("JsonProperty");
var metricAttr = p.GetAttr("Metric");
if (metricAttr == null) continue;
var propName = jsonPropertyAttr.GetFirstParameterValue();
var metricName = metricAttr.GetFirstParameterValue();
var newValue = $"data.{p.Identifier.ValueText}";
text.Append(
$"(metrics[$\"{{prefix}}{attrPrefix}_{propName}\"] as {metricName}).WithLabels(extraLabels.ToArray())");
switch (metricName)
{
case "Counter": text.AppendLine($".IncTo({newValue});"); break;
case "Gauge": text.AppendLine($".Set({newValue});"); break;
}
}
text.AppendLine("}").AppendLine();
return text;
}Bringing it all together with MetricCollection
Finally, we can use the generated code to bootstrap metrics on per-model basis and ensure we correctly handle updates:
internal class MetricCollection
{
private readonly Dictionary<string, Collector> _metrics;
private readonly string _prefix;
private readonly string _host;
public MetricCollection(IConfiguration configuration)
{
_prefix = configuration.GetValue<string>("exporterPrefix", "trex");
_metrics = new Dictionary<string, Collector>();
// this is where declaring particl classes and generating extra methods makes for seamless development experience
foreach (var (key, value) in TRexResponse.GetMetrics(_prefix)) _metrics.Add(key, value);
foreach (var (key, value) in DualStat.GetMetrics(_prefix)) _metrics.Add(key, value);
foreach (var (key, value) in Gpu.GetMetrics(_prefix)) _metrics.Add(key, value);
foreach (var (key, value) in Shares.GetMetrics(_prefix)) _metrics.Add(key, value);
}
public void Update(TRexResponse data)
{
TRexResponse.UpdateMetrics(_prefix, _metrics, data, _host, "main", data.Algorithm);
DualStat.UpdateMetrics(_prefix, _metrics, data.DualStat, _host, "dual", data.DualStat.Algorithm);
foreach (var dataGpu in data.Gpus)
{
Gpu.UpdateMetrics(_prefix, _metrics, dataGpu, _host, "main", data.Algorithm, new List<string>
{
dataGpu.DeviceId.ToString(),
dataGpu.Vendor,
dataGpu.Name
});
Shares.UpdateMetrics(_prefix, _metrics, dataGpu.Shares, _host, "main", data.Algorithm, new List<string>
{
dataGpu.GpuId.ToString(),
dataGpu.Vendor,
dataGpu.Name
});
}
}
}Peeking into generated code
Just to make sure we’re on the right track, we looked at generated code. It ain’t pretty but it’s honest work:
public partial class Shares {
public static Dictionary<string, Collector> GetMetrics(string prefix)
{
var result = new Dictionary<string, Collector>
{
{$"{prefix}_shares_accepted_count", Metrics.CreateCounter($"{prefix}_shares_accepted_count", "accepted_count", "host", "slot", "algo", "gpu_id", "vendor", "name") },
{$"{prefix}_shares_invalid_count", Metrics.CreateCounter($"{prefix}_shares_invalid_count", "invalid_count", "host", "slot", "algo", "gpu_id", "vendor", "name") },
{$"{prefix}_shares_last_share_diff", Metrics.CreateGauge($"{prefix}_shares_last_share_diff", "last_share_diff", "host", "slot", "algo", "gpu_id", "vendor", "name") },
...
};
return result;
}
public static void UpdateMetrics(string prefix, Dictionary<string, Collector> metrics, Shares data, string host, string slot, string algo, List<string> extraLabels = null) {
if(extraLabels == null) {
extraLabels = new List<string> {host, slot, algo};
}
else {
extraLabels.Insert(0, algo);
extraLabels.Insert(0, slot);
extraLabels.Insert(0, host);
}
(metrics[$"{prefix}_shares_accepted_count"] as Counter).WithLabels(extraLabels.ToArray()).IncTo(data.AcceptedCount);
(metrics[$"{prefix}_shares_invalid_count"] as Counter).WithLabels(extraLabels.ToArray()).IncTo(data.InvalidCount);
(metrics[$"{prefix}_shares_last_share_diff"] as Gauge).WithLabels(extraLabels.ToArray()).Set(data.LastShareDiff);
...
}
}Conclusion
This example barely scratches the surface of what’s possible with this feature. Source code generators are extremely helpful when we deal with tedious and repetitive development tasks. It also helps reduce maintenance overheads by enabling us to switch to declarative approach. I’m sure we will see more projects coming up where this feature will become central to the solution.
If not already, do check out the source code in GitHub. And as for us, we would like to sign off with warmest greetings of this festive season and best wishes for happiness in the New Year.